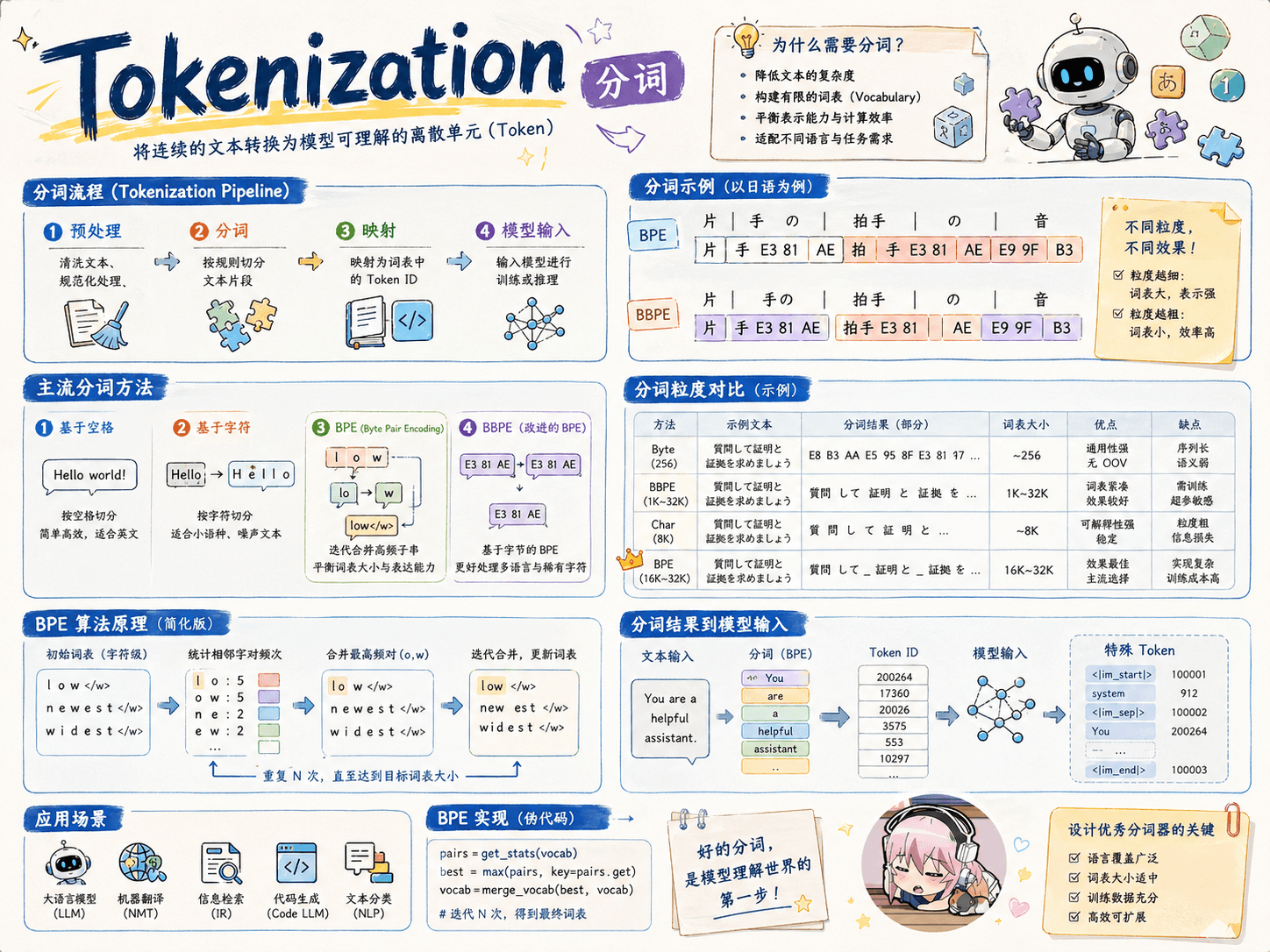
BPEByte Pair Encoding (BPE) 论文:Neural Machine Translation of Rare Words with Subword Units 核心思想:从一个基础小词表开始,通过不断合并最高频的连续 token 对来产生新的 token。 具体做法: 输入训练语料和期望词表大小 V。 准备基础词表:比如英文中 26 个字母加上各种符号,并初始化 ID。 Apr 30, 2026·1 min read·1
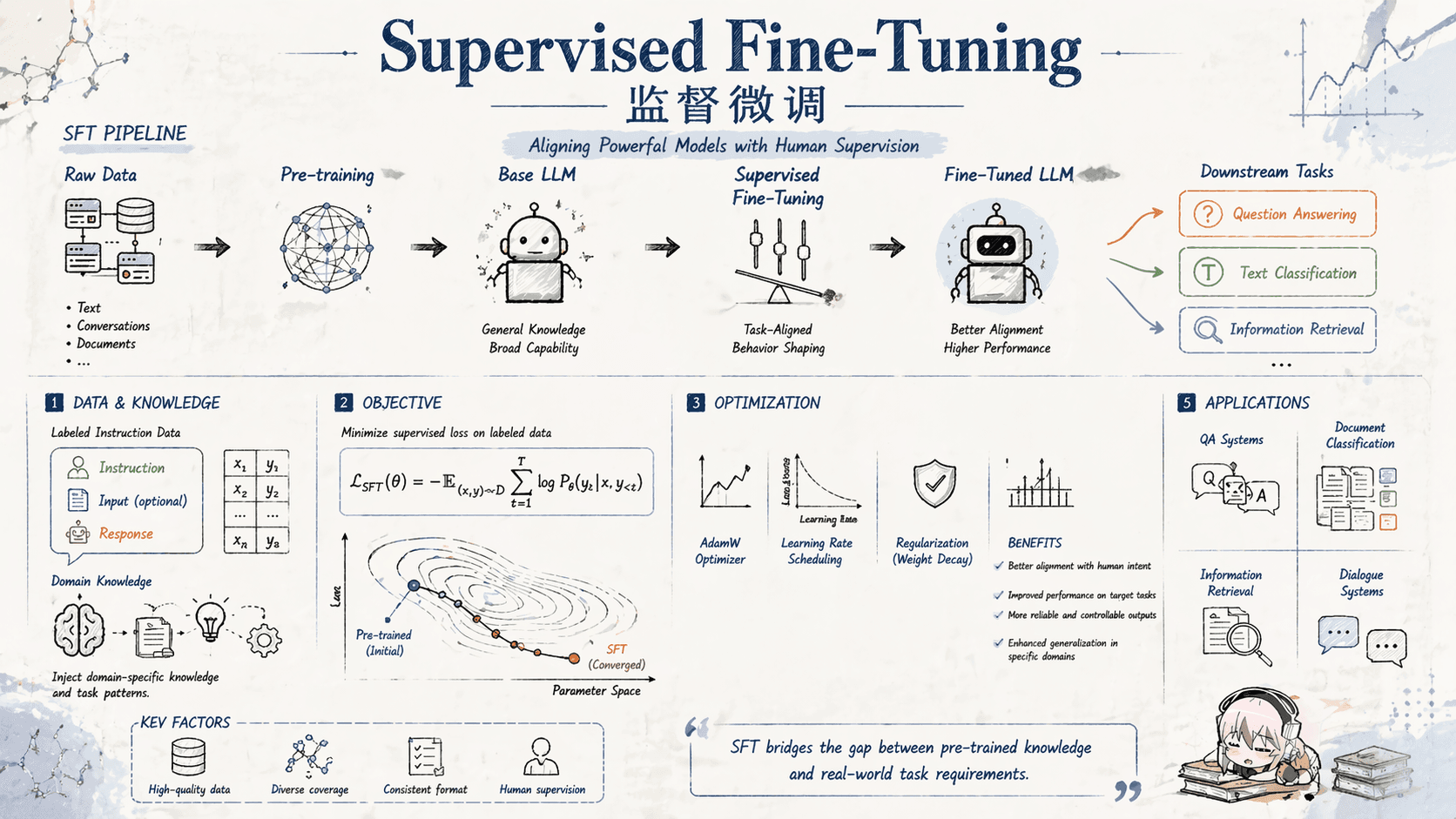
Supervised Fine-Tuning 监督微调SFT 简介 [!IMPORTANT] 🐲 监督微调 SFT 监督微调(Supervised Fine-Tuning,SFT):在已经完成预训练的大语言模型基础上,利用特定任务的标注数据集对模型参数进行进一步调整的技术过程。其核心逻辑在于:预训练模型已通过海量通用语料掌握了广泛的语言知识和模式,而 SFT 阶段则利用相对少量的高质量特定任务数据(通常为指令-回答对),引导模型将泛化能力收敛至具Apr 30, 2026·1 min read