Architecture 大模型整体架构

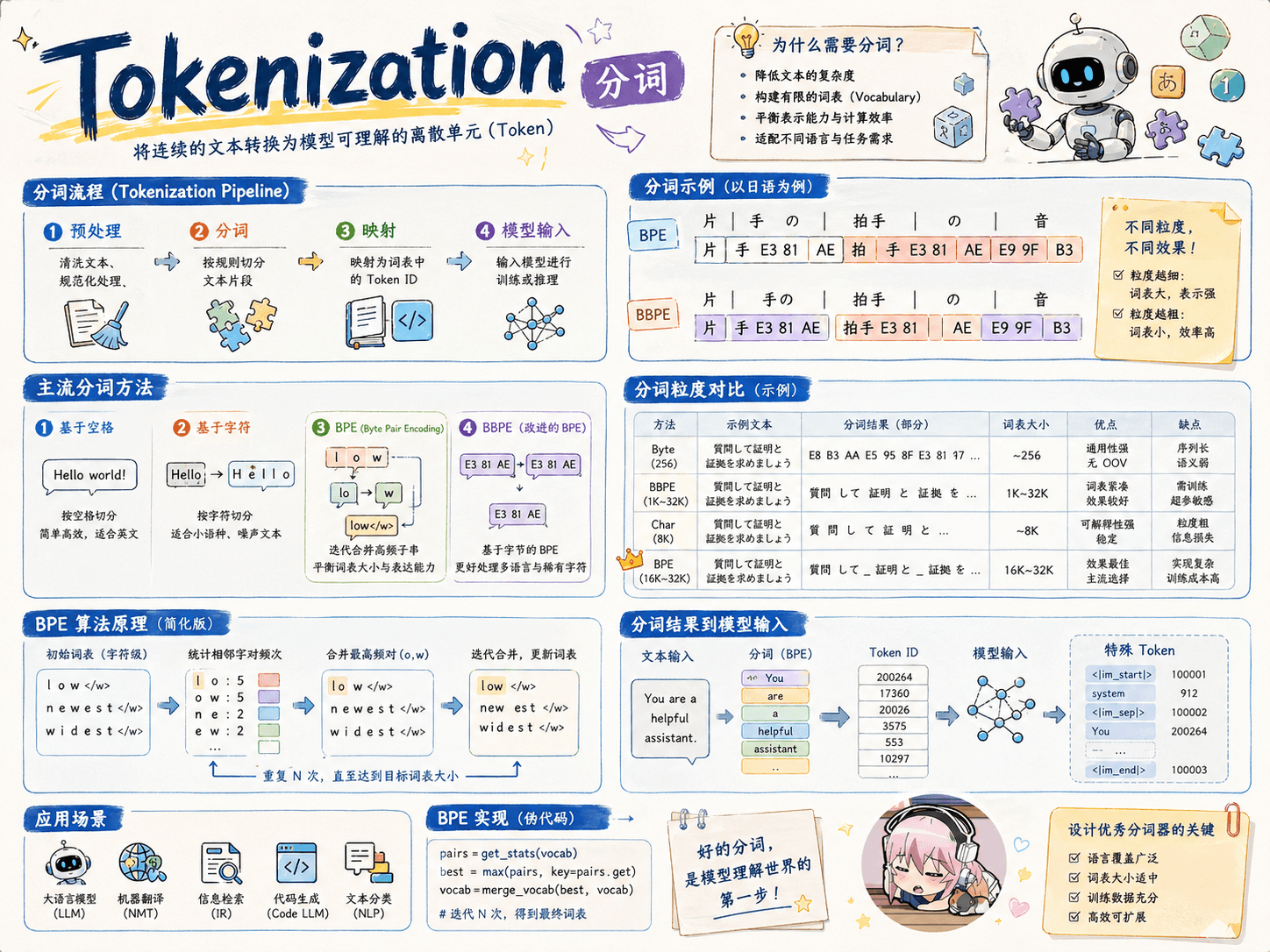
分词粒度
词粒度 word:英文天生使用空格分隔词汇,中文可使用 jieba 分词工具。
优点:词的边界和含义得到保留。
缺点:
由于长尾效应,词粒度的词表可能会非常大,包含很多的稀有词,存储和训练成本高,稀有词往往很难学习好。
OOV(out of vocabulary)问题:对词表之外的词无能为力。
无法处理单词的形态关系和词缀关系。同一个词的不同形态,语义相近,完全当做不同的单词不仅增加了训练成本,而且无法很好捕捉这些单词之间的关系;同时,无法学习词缀在不同单词之间的泛化。
字符粒度 char:能够解决 OOV 问题。
优点:词表极小。(26 个英文字母可以组出所有的词,5000 多个中文常用字基本也能够组合出足够的词汇,再加上一些常用字符)
缺点:
无法承载丰富的语义。
序列长度增长,带来计算成本的增长。
字词粒度 subword:粒度介于 char 和 word 之间,常用词保持原状,生僻词拆分成子词以共享 token 压缩空间。
优点:可以较好的平衡词表大小与语义表达能力,OOV 问题可以通过 subword 的组合来解决。
常见子词分词算法:
字节对编码(Byte Pair Encoding,BPE).
WordPiece.
Unigram Language Model.
1 views