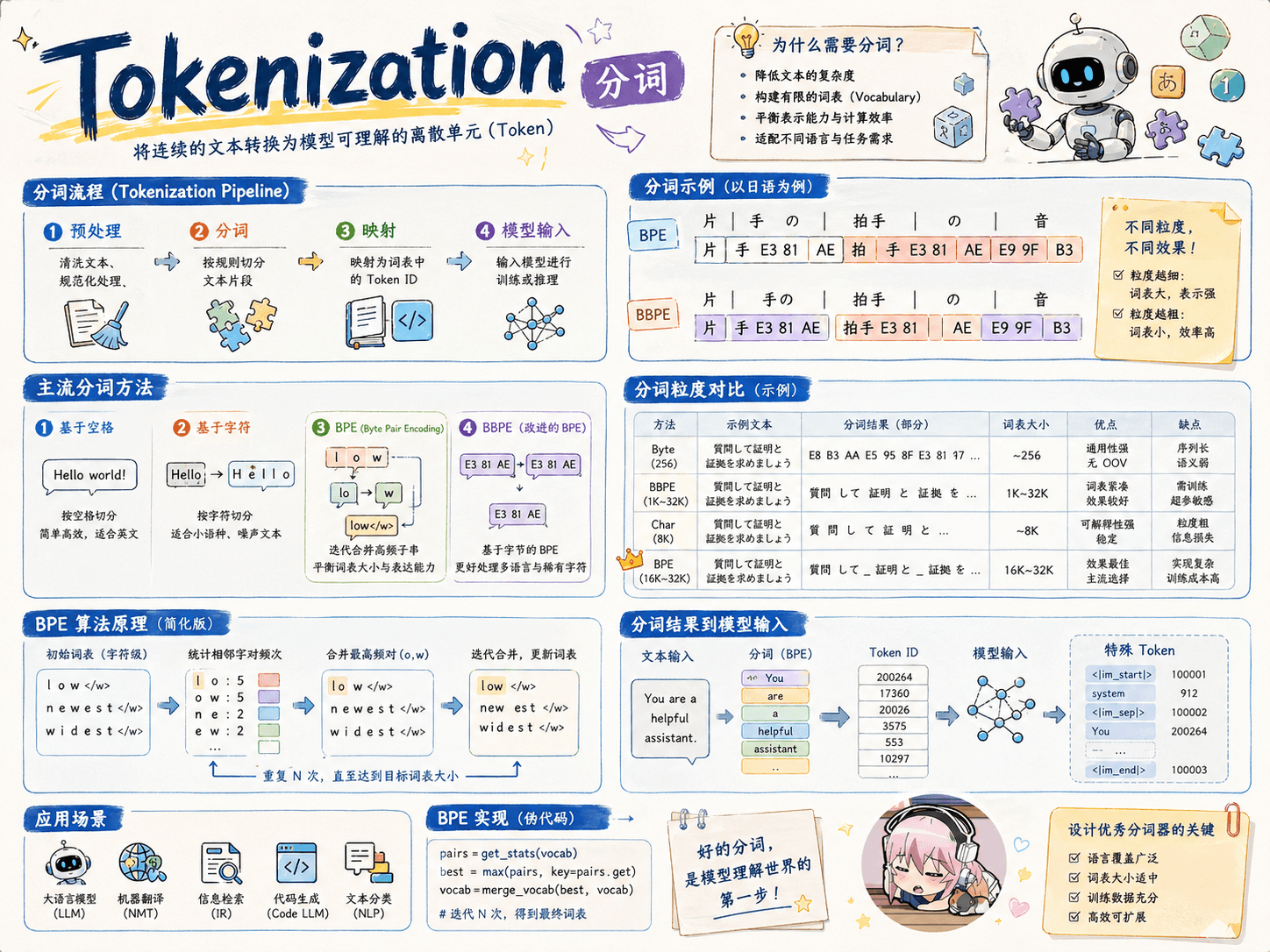
BPE

Byte Pair Encoding (BPE)
论文:Neural Machine Translation of Rare Words with Subword Units
核心思想:从一个基础小词表开始,通过不断合并最高频的连续 token 对来产生新的 token。
具体做法:
输入训练语料和期望词表大小 V。
准备基础词表:比如英文中 26 个字母加上各种符号,并初始化 ID。
基于基础词表将准备的语料拆分为最小单元。
在语料上统计单词内相邻单元对的频率,选择频率最高的单元对进行合并。
重复第 3 步直到达到预先设定的 subword 词表大小或下一个最高频率为 1。
优点:可以有效地平衡词汇表大小和编码步数(编码句子所需的 token 数量,与词表大小和粒度有关)。
缺点:
基于贪婪和确定的符号替换,不能提供带概率的多个分词结果(相对于 ULM 而言的);
解码的时候面临歧义问题(如:对于同一个句子
"Hello World",分词结果可能不同"Hell/o/world"或"He/llo/world")。
1 views