Tokenization 分词

Search for a command to run...
No comments yet. Be the first to comment.
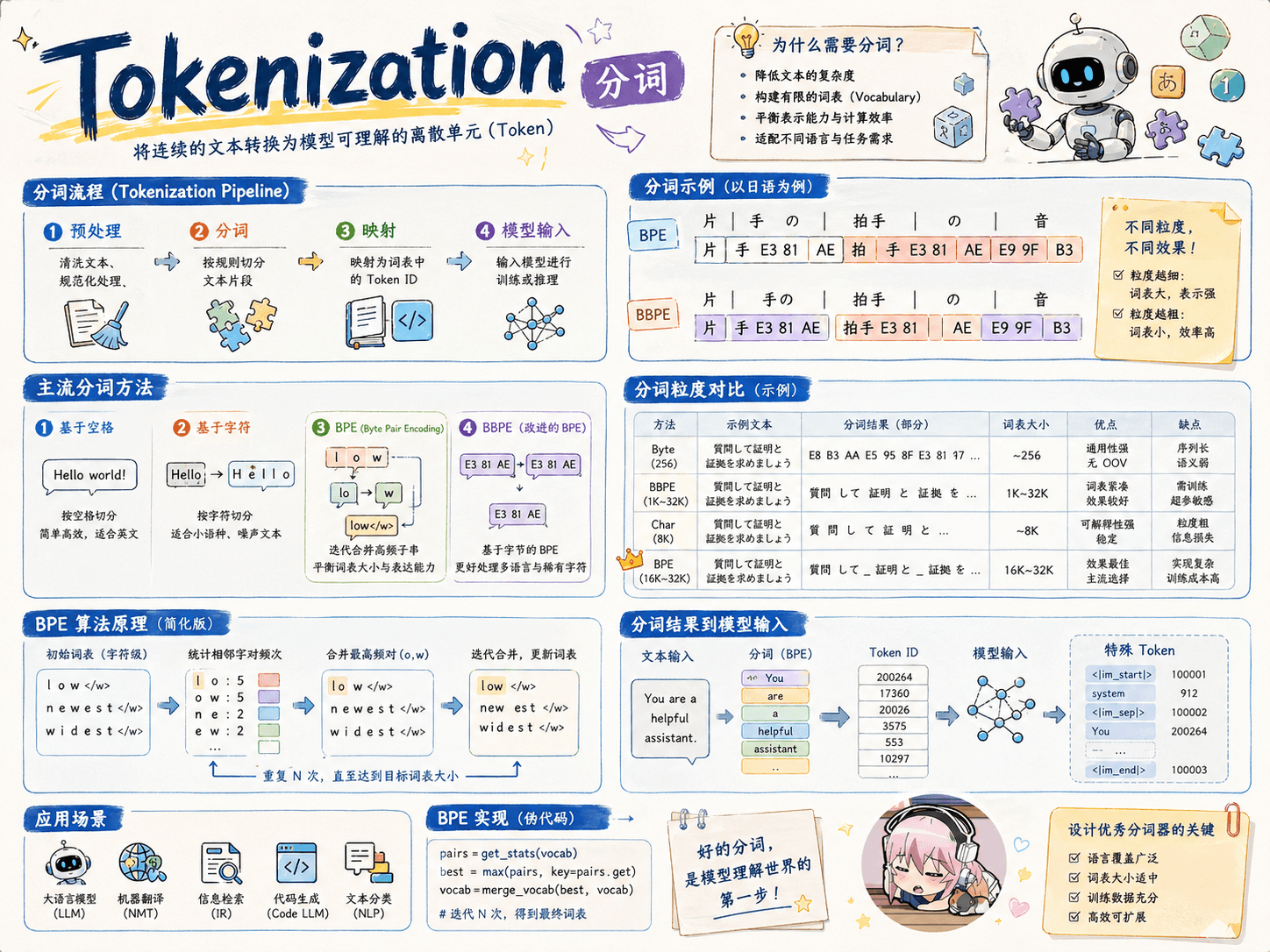
Byte Pair Encoding (BPE) 论文:Neural Machine Translation of Rare Words with Subword Units 核心思想:从一个基础小词表开始,通过不断合并最高频的连续 token 对来产生新的 token。 具体做法: 输入训练语料和期望词表大小 V。 准备基础词表:比如英文中 26 个字母加上各种符号,并初始化 ID。

分词粒度 词粒度 word:英文天生使用空格分隔词汇,中文可使用 jieba 分词工具。 优点:词的边界和含义得到保留。 缺点: 由于长尾效应,词粒度的词表可能会非常大,包含很多的稀有词,存储和训练成本高,稀有词往往很难学习好。 OOV(out of vocabulary)问题:对词表之外的词无能为力。 无法处理单词的形态关系和词缀关系。同一个词的不同形态,语义相近,完全当做不同的单词

基本概念 预训练:在大规模的通用数据集上对模型进行初步训练,在见到特定任务数据之前,使模型能够捕捉到数据的通用特征和模式,提升其在各种任务上的性能和泛化能力,同时减少对标注数据的依赖,生成一个具备基础能力的基座模型(base model) ,并加速模型在新任务上的训练和微调(fine-tuning)过程。在预训练期间,模型需要处理大量未标记的文本数据,例如书籍、文章和网站,目标是捕获文本语料库中存
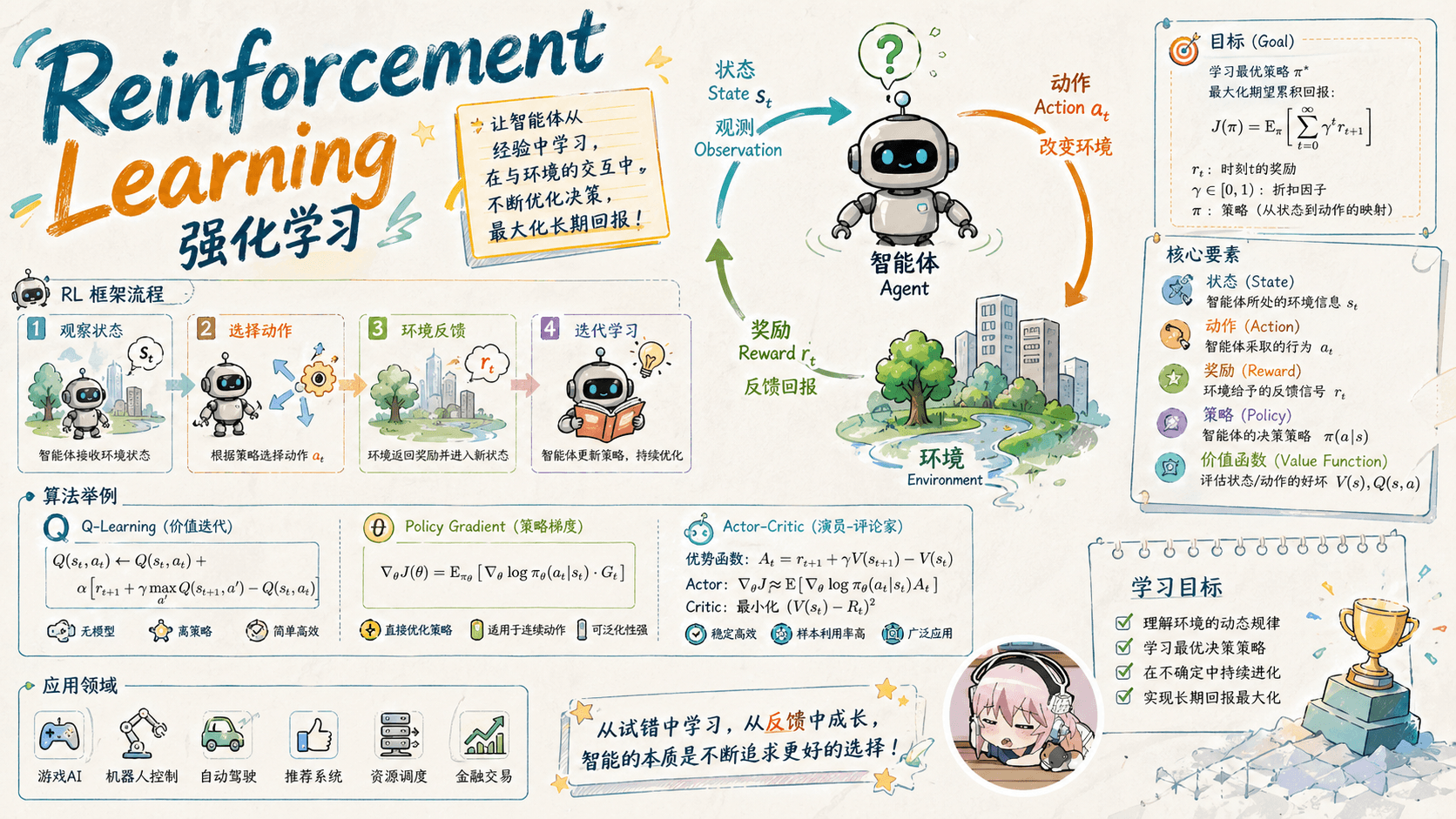
1. RL 简介 在机器学习领域,有一类重要的任务和人生选择很相似,即序贯决策(sequential decision making)任务。决策和预测任务不同,决策往往会带来“**后果 ” ,因此决策者需要为未来负责,在未来的时间点做出进一步的决策。实现序贯决策的机器学习方法就是强化学习(reinforcement learning)** 。预测仅仅产生一个针对输入数据的信号,并期望它和未来可观测
明天不熬夜
6 posts