Supervised Fine-Tuning 监督微调
SFT 简介
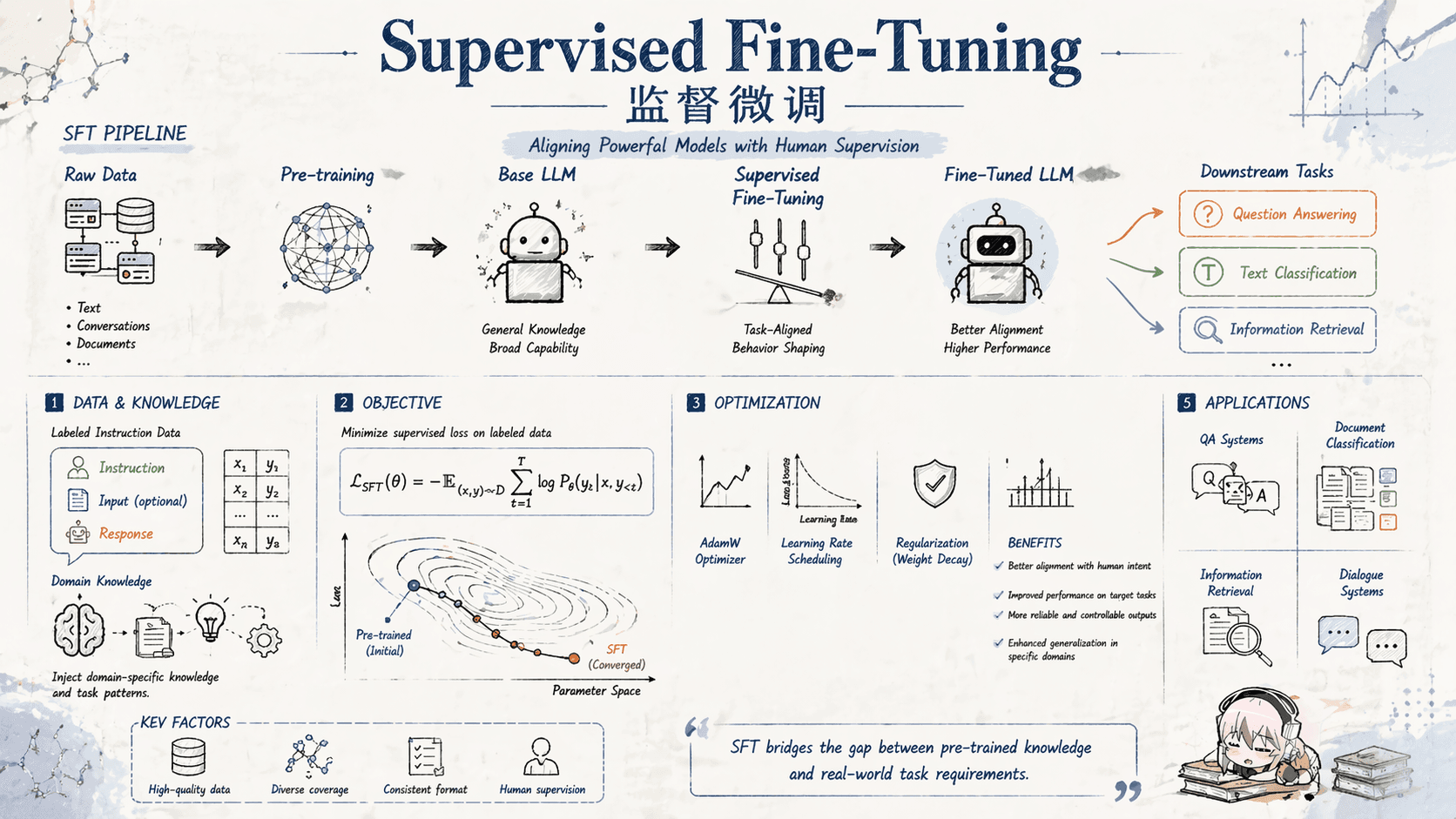
[!IMPORTANT] 🐲 监督微调 SFT 监督微调(Supervised Fine-Tuning,SFT):在已经完成预训练的大语言模型基础上,利用特定任务的标注数据集对模型参数进行进一步调整的技术过程。其核心逻辑在于:预训练模型已通过海量通用语料掌握了广泛的语言知识和模式,而 SFT 阶段则利用相对少量的高质量特定任务数据(通常为指令-回答对),引导模型将泛化能力收敛至具体应用场景,从而显著提升模型在该任务上的表现。
在实际执行中,SFT 的数据集通常由若干条样本构成,每条样本包含明确的指令(Instruction) 和对应的标准回答(Answer) ,其数学形式表示为:
$$> D={(I_{K},A_{K})}_{K=1}^{N} >$$
此外,在 SFT 阶段模型规模的选择尤为关键:参数量较小的模型在处理有限数据量或计算资源受限的场景下效率更高、表现稳健;而参****数量巨大的模型(如 GPT-4 级别)则更擅长捕捉复杂模式,在数据丰富、任务逻辑艰深的环境中表现更为出色。